Como contêineres funcionam?
Postado em 19 January, 2022 | 9 minutosSumário
Obs.: Originalmente publicado no computando-arte dia 19Janeiro2022
Existe muito hype quando o assunto é contêineres e Kubernetes, isso acaba gerando uma expectativa e confusão do que são e como funcionam essas tecnologias.
Hoje vamos falar o que de fato é um contêiner, como funciona e se cria um contêiner do zero (sem o docker).

Foto de ines mills, unsplash
O que é um contêiner?
Um contêiner é um processo rodando no kernel linux. E esse processo é isolado dos outros processos/contêineres e do host (através de features do kernel).
Essa é a principal diferença dos contêineres para máquinas virtuais (VM). Todos os contêineres compartilham o mesmo kernel, no passo que cada VM tem seu kernel.
Mas se é um kernel linux, como funciona quando uso o docker no Windows ou Mac? No fundo no Windows (mesmo WSL) e Mac tem uma máquina virtual rodando o linux.
E quais são essas features do kernel que fazem tudo isso acontecer? Vamos falar delas nesse texto.
Namespaces
Namespaces controlam o que um processo/contêiner consegue ver, existem atualmente os seguintes namespaces:
- Processes ID (pid)
- mount points (mnt)
- Network (net)
- IDs do usúario e group (user)
- Interprocess communication (ipc)
- Control Group (cgroup)
- Unix Timesharing System (uts), apesar do nome complicado, representa o hostname e domínios.
/proc
O procfs (montado em /proc) é um tipo de filesystem especial, nele existem diversas informações do sistema como CPU, memória e principalmente os processos.
Se quiser entender como ler as infos do /proc, veja em man proc.
Para que os processos do host ficarem isolados do contêiner, o contêiner precisa ter um /proc próprio (além de um namespace pid).
chroot
Para que o contêiner não acesse os arquivos do host, o chroot (change root directory) faz com que o contêiner só consiga acessar um diretório do host.
Por exemplo, se fizermos um chroot /mnt/root, um arquivo em /mnt/root/arq1.txt no host será apenas /arq01.txt no chroot. Neste chroot só consegue acessar o que está em /mnt/root
Control groups (cgroup)

:(){ :|:& };:
Provavelmente é a forkbomb mais conhecida. Uma forkbomb é um ataque que quando executada são rapidamente criados muitos processos que que se multiplicam exponencialmente incapacitando totalmente o computador, sério! Só tirando da tomada pra conseguir parar.
Precisamos de uma forma de limitar quantos recursos um determinado contêiner consegue utilizar. Os control group (cgroup) limitam os recursos como CPU, memória, rede que cada contêiner pode utilizar.
Demo: Criando um contêiner do zero
Bora criar nosso contêiner sem usar o docker! Antes de tudo precisamos instalar o que vamos precisar:
sudo apt install debootstrap cgroup-tools util-linux
Primeiramente vamos criar uma instalação base do debian, para que o que fizermos no contêiner não contamine nossa máquina (o host), rode o seguinte no terminal:
sudo debootstrap bullseye ./deb11-rootfs https://deb.debian.org/debian/
O comando acima vai criar uma instalação do Debian 11 (bullseye) na pasta deb11-rootfs.
Agora vamos criar um cgroup
export cgroup_name="cg_$(shuf -i 2000-3000 -n 1)"
cgcreate -g "cpu,cpuacct,memory,pids:$cgroup_name"Colocando limites no cgroup:
cgset -r cpu.shares=256 "$cgroup_name"
cgset -r memory.limit_in_bytes=100M "$cgroup_name"
cgset -r pids.max=100 "$cgroup_name"Então nosso cgroup vai ter no máximo 100MB de RAM, 1/4 de cpu (256/1024 shares) e 100 processos simultâneos então uma forkbomb vai ser contida.
É agora, bora disparar um contêiner nesse cgroup:
cgexec -g "cpu,cpuacct,memory,pids:$cgroup_name" \
unshare --fork --mount --uts --ipc --pid --mount-proc \
chroot "./debian11-rootfs" \
/bin/sh -c "/bin/mount -t proc proc /proc && hostname container && /bin/bash"Calma, muita coisa ao mesmo tempo, vamos rodar o unshare no cgroup, o unshare vai criar os namespaces que queremos (uts, ipc e pid), então fazer um chroot no debian, montar um /proc próprio, mudar o hostname para contêiner e abrir um shell bash.
Sucesso! Temos um contêiner! O que vamos fazer?
Vamos ver que o contêiner não consegue ver os processos do host, faça ps aux (para listar os processos) e veja que são apenas listados os processos do contêiner, isso aconteceu porque o contêiner está num namespace pid (veja –pid no unshare e um /proc próprio).
Mas o host consegue ver o contêiner, faça sleep 1000 no contêiner e no host faça ps aux | grep 'sleep 1000', o host consegue ver todos os contêineres, repare que os mesmos processos no host tem um pid enquanto no contêiner tem outro PID.
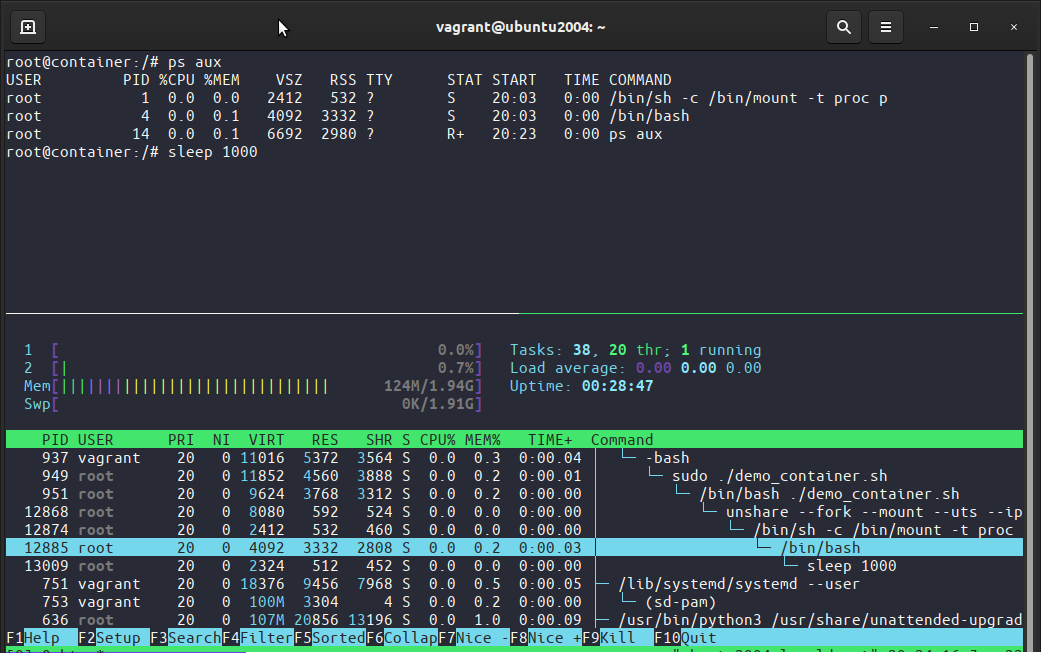
Veja que o contêiner só consegue enxergar seus processos, ao passo que o host (parte inferior) consegue ver os processos do(s) contêiner(s), veja também que o processo bash no contêiner tem PID 4 enquanto no host 12885.
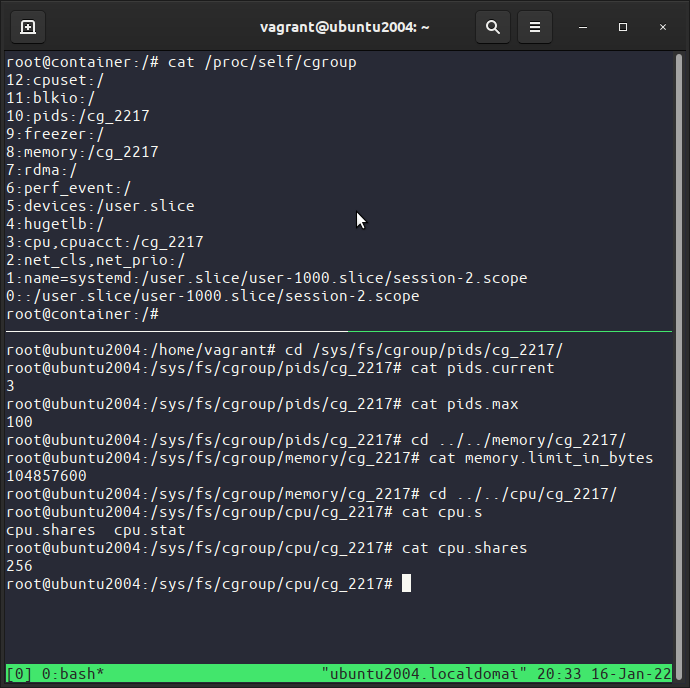
Faça cat /proc/self/cgroup no contêiner e compare com o host, esse arquivo lista os cgroups do processo, repare que os cgroup pids,memory,cpu,cpuacct são o cgroup que criamos.
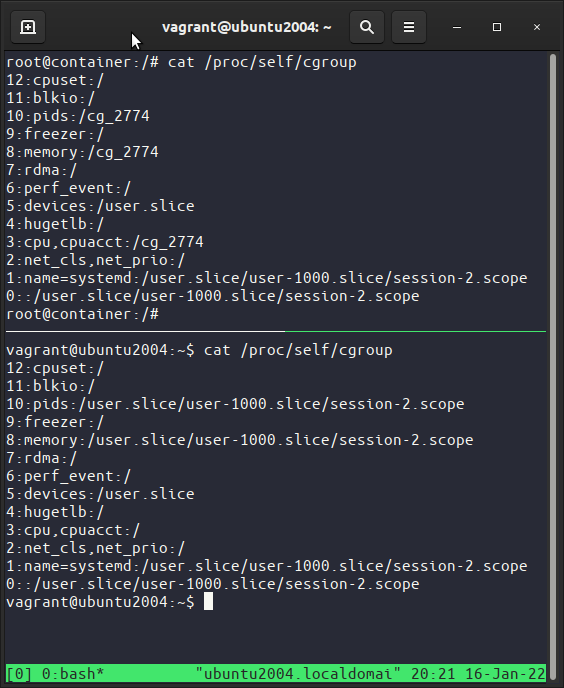
No host vá em /sys/fs/cgroup/ e navegue por exemplo em pid/nome_do_cgroup veja que tem vários arquivos informando infos e limites como pids.current e pids.max.
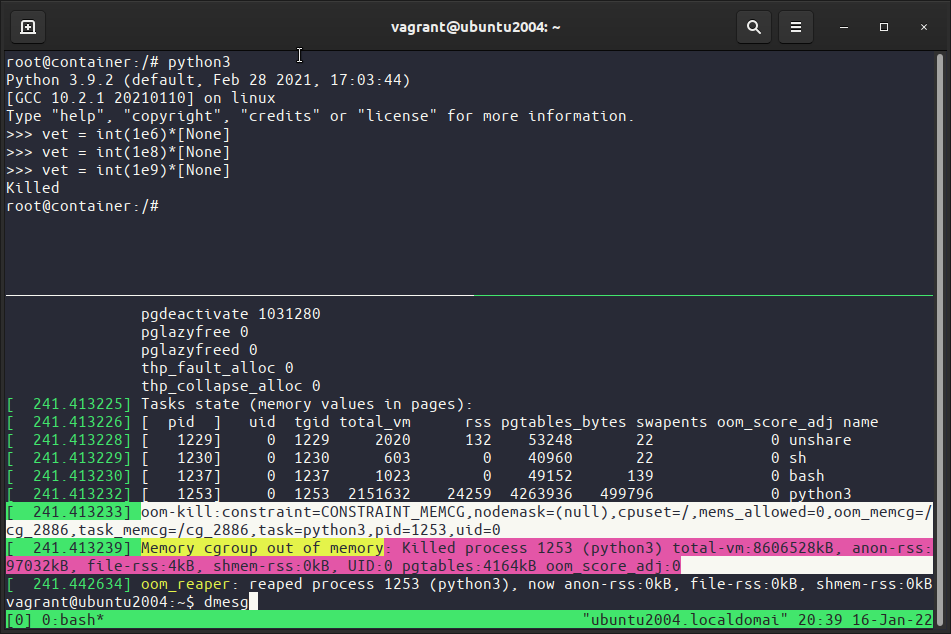
Por fim vamos testar esses limites, no contêiner instale o python (apt update && apt install python3) então abra o python e faça vet = int(1e9)*[None], tentamos alocar um vetor com 1 bilhão (1e9) valores, apareceu o Killed. O que aconteceu? No host faça dmesg (que exibe mensagens do kernel) e veja que o kernel (out of memory (oom)) matou processo pois ele passou do constraint.

Para facilitar coloquei os comandos que usamos para criar um contêiner em um script:
|
|
Overlay filesystems
No nosso exemplo usamos uma instalação do debian como filesystem, dessa forma cada contêiner precisaria ter sua própria instalação, gastando muito espaço de disco (sem aproveitar o que é comum).
Os filesystem overlay permitem que contêineres diferentes aproveitem o mesmo espaço em disco. Isso acontece através das camadas que são reutilizadas e empilhadas para criar o filesystem final de cada contêiner.
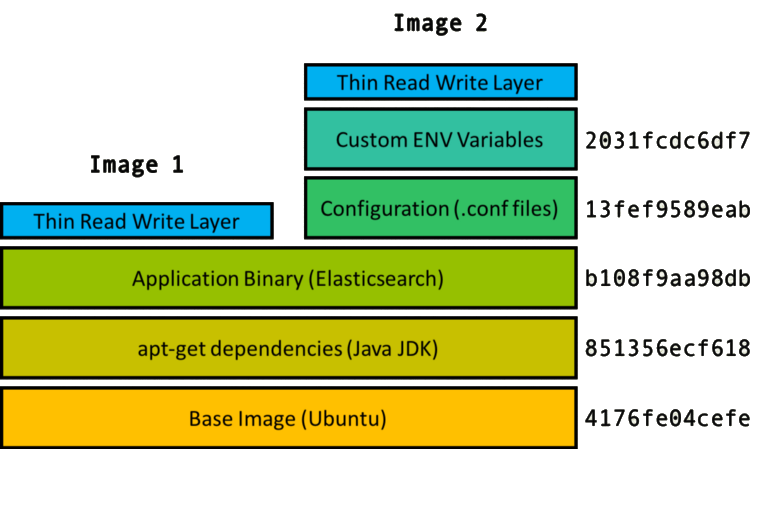
Na figura acima temos uma visualização bacana, partimos de uma instalação do sistema operacional Ubuntu, então é instalado o java e por fim são copiados os binários da aplicação elasticsearch essa é a imagem 1 (representada na 3a camada b108…). A imagem 2 são adicionados arquivos de configuração e por fim definidas algumas variáveis de ambiente.
Cada passo é uma camada (representada à direita), aproveitando aquela ação para outras imagens que usam aquilo como base.
Features de segurança
Capabilities, seccomp e apparmor são features de segurança para restringir o que os contêineres podem fazer, vamos falar brevemente delas a seguir:
- Capabilities: São permissões especiais que permitem processos fazer determinadas ações. Por exemplo cap_net_bind_service permite usar portas privilegiadas (<=1024). As capabilities surgiram para dar permissões mais granulares aos programas, antes delas essas ações só eram permitidas para o root.
- seccomp-bpf: Define quais chamadas de sistema (syscalls) são permitidas.
- AppArmor ou SELinux: São sistemas concorrentes normalmente distribuições baseadas no RedHat (como fedora) usam o SELinux enquanto distros baseadas no Debian (como Ubuntu, linux mint e pop-os) usam o AppArmor. Eles tem um perfil que define quais arquivos podem ser acessados (ou não) e quais capabilities são permitidas.
Quem faz tudo isso acontecer?
Quem já usa docker não precisa criar os namespaces, cgroups etc … que falamos aqui, então quem faz isso? O docker? Quem se ocupa disso são os contêiner runtime.
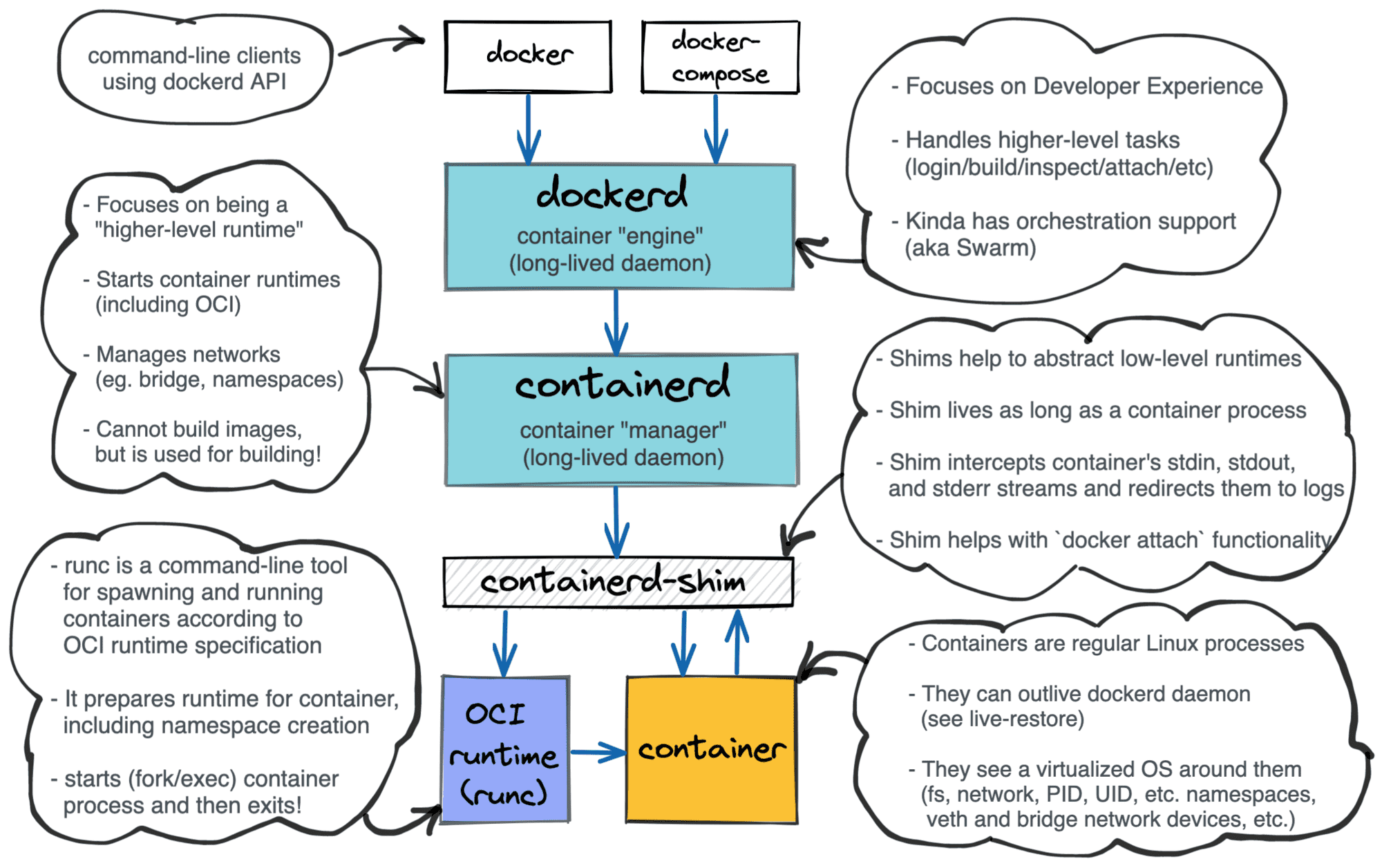
O diagrama acima mostra como tudo se relaciona, ao longo dos anos foram sendo criadas interfaces padronizadas, primeiramente a OCI (open containers iniciative) em jun/2015 e nasceu o runc. Depois foi criada a CRI (contêiner runtime interface) em Dez/2016 e nasceu o containerd.
Essas interfaces foram criadas principalmente por causa do Kubernetes, e com elas sendo padronizadas esses componentes podem ser substituídos facilmente. Por exemplo, se não quiser usar o containerd você pode usar uma alternativa mais leve como o cri-o.
Lembra em 2020 que na versão 1.20 do Kubernetes que o docker não ia ser mais suportado? Isso aconteceu porque o Kubernetes interagia com o docker de uma forma não padronizada. O dockershim não era a interface padronizada CRI, então o Kubernetes tinha que manter duas implementações separadas. Mais detalhes aqui: Não entre em pânico: Kubernetes e Docker
Tem uma talk legal que conta a história dessas interfaces: Below Kubernetes: Demystifying container runtimes
Rootless
Por padrão o docker daemon (e o containerd) roda como root no host, caso um contêiner consiga escapar o isolamento isso vai comprometer totalmente o computador host.
Uma vulnerabilidade grave no runc foi a CVE-2019-5736 que permitia um contêiner escapar e ter acesso root no host.
Rootless roda o docker (e os runtimes) como um usuário não root, trazendo um avanço significativo de segurança.
Até então o modo rootless no docker era experimental, mas na versão 20.10 (lançado em dez/2020) virou estável.
Um site ótimo que fala sobre contêineres rootless é o rootlesscontaine.rs, ele explica como tudo funciona e as instruções de como usar.
Conclusão

Vimos as primitivas do kernel Linux que fazem os contêineres funcionarem e as diferenças com máquinas virtuais, quem se interessou e quiser aprender mais vou deixar algumas referências.
Pra quem tá começando recomendo os seguintes materiais:
- docker-curriculum.com: É um tutorial bem prático e completo.
- Descomplicando Docker: Curso do LINUXtips em português brasileiro, a LINUXtips tem vários cursos excelentes de Devops.
- Docker Mastery: É o curso que mais gosto ;) ele é bem completo e passa várias dicas para depurar os contêineres e ainda faz uma breve introdução sobre orquestração de contêineres (docker swarm e kubernetes).
Para montar esse texto usei o livro da Liz Rice: Container Security: Fundamental Technology Concepts that Protect Containerized Applications, é bem completo e quem curte segurança vai adorar. A mesma autora tem uma talk legal Building a conteiner from scratch in Go.