Primeiros passos com o pandas
Postado em 30 November, 2020 | 8 minutosSumário
Obs.: Originalmente publicado no computando-arte dia 30Nov2020
O que é o pandas
Pandas é uma biblioteca Python para trabalhar com dados tabulares, que como o nome sugere são os dados estruturados na forma de uma tabela: ou seja os elementos são arranjados em colunas verticais e linhas (ou registros) horizontais, dessa forma cada elemento é formado pela intersecção de uma coluna e uma linha.
É uma das biblioteca mais importantes para Ciência de Dados. As principais bibliotecas são:
- Aprendizado de máquina: scikit-learn
- Vetores e matrizes: numpy
- Scipy: várias coisas científicas(computação científica) 😜
- Gráficos: matplotlib, seaborn, plotly
- Redes neurais: pytorch e tensorflow
Sobre a linguagem Python
Python é umas das principais linguagens de programação usada em Ciência de Dados, é uma linguagem fácil de aprender e existem muitas bibliotecas excelentes disponíveis. Além de Python, a linguagem R também é muito utilizada.
- Quer aprender Python? Recomendo o livro do Luciano Ramalho: Python Fluente. Quer uma palinha? Ele fez uma live: Luciano Ramalho – A Beleza de Python.
- Não curte livro? O Fernando Masanori fez uma série de vídeos: python para zumbis.
- Canais do youtube: Dunossauro (Eduardo Mendes) e o canal Programação dinâmica tem vários vídeos excelentes.
- Já manja de programar e quer só aprender como faço determinada tarefa em Python: pythoncheatsheet.org
- Praticar: tem um “jogo” que são dados alguns problemas para serem resolvidos em Python: py.checkio.org
- Curte minecraft? Na Raspberry Pi é possível interagir em Python com o jogo: projects.raspberrypi.org/en/projects/getting-started-with-minecraft-pi.
Jupyter notebooks e como preparar seu ambiente
Quando estiver programando em Python ou outras linguagens interpretadas, uma opção popular é a utilização de Jupyter Notebooks. O Jupyter Notebook é uma espécie de “caderno com células” com código ou texto, que pode ser formatado com Markdown (inclusive com formulas LaTeX). Dessa forma, é possível escrever uma vez só o código que gera os gráficos, resultados, texto para um artigo, slides, e etc. Além de que as células são executadas de forma interativa, tornando-se mais fácil de programar dessa forma.
Dicas para os Jupyter notebooks:
- Para usar o jupyter é simples, crie a célula e use shift+enter para executar aquela célula.
- Precisa instalar um pacote? coloque um ! antes do comando que quer instalar, por exemplo:
!pip install numpy - Coloque ? antes do que você quer procurar o manual, por exemplo a função split em strings:
?str.split. Então, será aberto um painel com o manual dessa função. - Como instalar tudo? O jeito mais simples é usar o anaconda.com que instala todo ambiente Python em sua máquina de maneira simples.
- Outra opção é programar direto do navegador sem precisar instalar nada: o colab.research.google.com é uma opção popular, e ainda usufrui de GPUs para treinar redes neurais rapidamente e gratuito.
- Pra quem curte software livre e não quer usar a plataforma do google o cocalc.com é uma ótima opção.
Começando pelo começo: séries de valores no pandas
Antes de tudo, vamos importar o pandas:
import pandas as pdVamos escrever uma série de valores. Podemos definir os índices da serie de valores, tornando a mais completa e fácil de entender e acessar.
gasto_semana = pd.Series([20,40,50,30,40,80,15])
gasto_semana.index = [“domingo”, “segunda”, “terca”, “quarta”, “quinta”, “sexta”, “sabado”]
gasto_semana
domingo 20
segunda 40
terca 50
quarta 30
quinta 40
sexta 80
sabado 15
dtype: int64Para acessar os valores procedemos da mesma forma que com listas: gasto_semana[“segunda”]. Dessa forma, o valor a ser retornado será o valor da segunda-feira.
Também temos a flexibilidade de realizar cálculos, por exemplo elevar ao quadrado os gastos da semana ao quadrado:
gasto_semana**2
domingo 400
segunda 1600
terca 2500
quarta 900
quinta 1600
sexta 6400
sabado 225
dtype: int64Uma vez que a série foi criada, podemos, por exemplo, calcular a mediana, as estatísticas descritivas (média, desvio padrão, quartis, e etc.) e contar os valores únicos da série:
gasto_semana.median()
40.0gasto_semana.describe(percentiles = [.25, .5, .75])
count 7.000000
mean 39.285714
std 21.684974
min 15.000000
25% 25.000000
50% 40.000000
75% 45.000000
max 80.000000
dtype: float64gasto_semana.value_counts(normalize=False)
40 2
15 1
30 1
20 1
80 1
50 1
dtype: int64Podemos procurar por valores que satisfazem uma determinada condição:
gasto_semana > 30
domingo False
segunda True
terca True
quarta False
quinta True
sexta True
sabado False
dtype: boolRepare que a saída é uma série com os mesmos índices da serie original e com valores True ou False para os valores que satisfazem ou não a condição.
Um detalhe é que se quisermos procurar por valores que satisfazem diversas condições, temos que os usar operadores bitwise, por exemplo E (and) é representado por &, OU (or) por | e negação (NOT) por ~
(gasto_semana > 30) & (gasto_semana < 80)
domingo False
segunda True
terca True
quarta False
quinta True
sexta False
sabado False
dtype: boolPor fim, se usarmos isso dentro da série original, vamos gerar uma serie com os valores que satisfazem as condições:
gasto_semana[(gasto_semana > 30) & (gasto_semana < 80)]
segunda 40
terca 50
quinta 40
dtype: int64Dataframes
Dataframe é um estrutura bidimensional de dados. Pense em dataframe como uma tabela ou matriz. No fundo, o dataframe tem algumas colunas onde cada coluna é uma série de dados e as colunas são “amarradas” pelos índices.
Vamos importar um dataframe de gorjetas, onde foram anotadas diversas informações de gorjetas como sexo, se é fumante ou não, dia da semana, quantas pessoas na mesa, e etc.
import seaborn as sns
tips_df = sns.load_dataset(“tips”)
tips_df.head(6) # exibe os 6 primeiros registros (use tail para ultimos)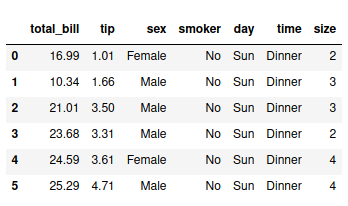
Uma das primeiras coisas que eu gosto de fazer assim que importo os dados é utilizar a função info para vermos se o type de cada coluna foi identificado corretamente.
E também podemos ver quanto de memória é utilizada. Caso o conjunto de dados seja grande, é interessante tentar alguns “truques” como transformar alguma coluna como categórico para poupar memória 😜
tips_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.3 KBSe quisermos saber qual o percentual de quem paga a gorjeta e é fumante, podemos utilizar o values_count conforme descrito na célula de código abaixo. Assim, saberemos que aproximadamente 60% dos pagantes de gorjeta fumam.
tips_df[‘smoker’].value_counts(normalize=True)
No 0.618852
Yes 0.381148
Name: smoker, dtype: float64Podemos criar também colunas novas. Vamos calcular o total pago (total = valor_conta + valor_tip) e a porcentagem do valor da gorjeta com o total:
tips_df[‘total_payed’] = tips_df[“total_bill”] + tips_df[“tip”]
tips_df[‘tip_percentage’] = 100.0*tips_df[“tip”]/tips_df[“total_bill”]
tips_df.head()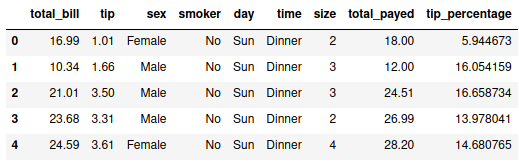
Qual é a distribuição de percentagem da gorjeta? E do valor total?
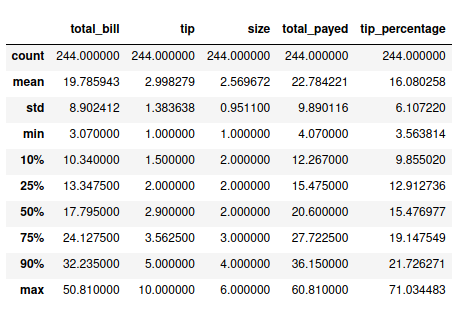
Como podemos ver, em média as gorjetas representam 15% do valor da conta, o que corresponde a ao valor médio da gorjeta de 2.9 dólares.
Referente ao valor total, a média é de 20.6 dólares e mediana de 22.8 dólares.
Fumantes tendem a pagar mais gorjeta? Podemos agrupar os valores pela coluna smoker e fazer um describe
tips_df.groupby([‘smoker’]).tip_percentage.describe()

Aparentemente não faz muita diferença se o cliente é fumante ou não para pagar um percentual maior de gorjeta (mediana ficou 15.4% para fumantes e 15.6% para não fumantes).
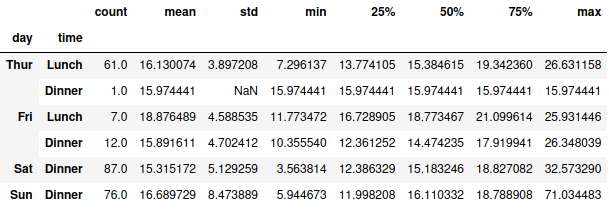
E o dia da semana junto com o dia? Faz diferença? Podemos agrupar com mais de uma coluna
tips_df.groupby([‘day’, ‘time’]).tip_percentage.describe()
E gráficos? Fazer gráficos com o pandas é muito simples:
tips_df.plot.scatter(x=’total_bill’,y=’tip_percentage’)
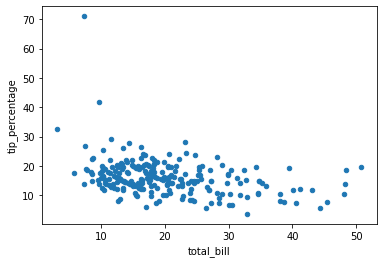
Neste gráfico queremos ver se existe uma correlação entre o valor conta e o percentual de gorjeta concedido. Vemos que pelo contrario, uma leve correlação negativa: quanto maior o valor da conta menos será pago de gorjeta, percentualmente.
Outra opção é usar a biblioteca de gráficos seaborn, que além de ser fácil de usar, os gráficos ficam bem bonitos
import seaborn as sns
sns.scatterplot(data=tips_df, x=’total_bill’,y=’tip_percentage’, hue=’smoker’)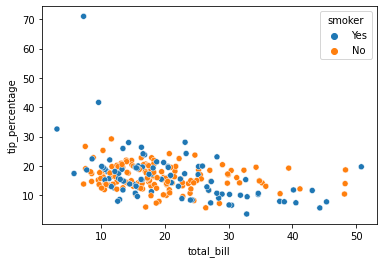
Ler e gravar os dados
Para ler dados com pandas é super simples. Por exemplo, para ler um csv basta fazer (inclusive funciona se passar o link do csv):
df = pd.read_csv('arquivo.csv')
É possível ler de arquivos excel com pd.read_excel, HDF5, SQL, inclusive Parquet — um formato muito usado em Big Data. Para salvar o arquivo basta fazer df.to_csv(‘arquivo.csc’), e etc.
Dicas legais
Raspagem web: o pandas consegue extrair tabelas de páginas web. Para isso, basta usar a função pd.read_html(<link_da_pagina>), assim como mágica o pandas lê a tabela como um dataframe.
Pivot tables: se você está acostumado a fazer pivot tables como no excel, o pandas faz facilmente através da função pd.pivot_table, conforme o exemplo abaixo:
pd.pivot_table(tips_df, index=’size’, columns=’smoker’, values=’tip_percentage’, aggfunc=’median’)
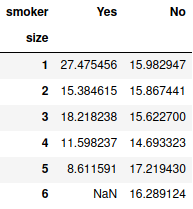
Fizemos uma pivot table onde as linhas são quantas pessoas tem à mesa, as colunas significam se o cliente é fumante ou não, e os valores são a porcentagem da gorjeta agregada com mediana.
Conclusão
Como vimos, o pandas é uma biblioteca muito fácil de usar e que faz mágica. Para aprender mais, existe o guia de usuário com o passo-a-passo e a documentação oficial. Outra referência legal e rapidinha são as dicas do Kevin Markham, ele montou uma lista com 100 dicas ótimas para usar pandas: dataschool.io/python-pandas-tips-and-tricks/.